人工智能的新希望-强化学习全解
很多人说,强化学习被认为是真正的人工智能的希望。本文将从7个方面带你入门强化学习,读完本文,希望你对强化学习及实战中实现算法有着更透彻的了解。很多人说,强化学习被认为是真正的人工智能的希望。本文将从7个方面带你入门强化学习,读完本文,希望你对强化学习及实战中实现算法有着更透彻的了解。

很多人说,强化学习被认为是真正的人工智能的希望。本文将从7个方面带你入门强化学习,读完本文,希望你对强化学习及实战中实现算法有着更透彻的了解。
许多科学家都在研究的一个最基本的问题是“人类如何学习新技能?”。 理由显而易见 如果我们能解答这个问题,人类就能做到很多我们以前没想到的事情。 另一种可能是我们训练机器去做更多的“人类”任务,创造出真正的人工智能。
虽然我们还没有上述问题的全部答案,但有一些事情是清楚的。不论哪种技能,我们都是先通过与的互动来学习它。无论是学习驾驶汽车还是婴儿学步,我们的学习都是基于与的互动。 从这些互动中学习是所有关于学习与智力的理论的基础概念。
今天我们将探讨强化学习(Re-inforcement Learning) 一种基于与互动的目标导向的学习。强化学习被认为是真正的人工智能的希望。我们认为这是正确的说法,因为强化学习拥有巨大的潜力。
强化学习正在迅速发展。它已经为不同的应用构建了相应的机器学习算法。因此,熟悉强化学习的技术会对深入学习和使用机器学习非常有帮助。如果您还没听说过强化学习,我您阅读我之前关于强化学习和开源强化学习(RL)平台的介绍文章
如果您已经了解了一些强化学习的基础知识,请继续阅读本文。读完本文,您将会对强化学习及实战中实现算法有着更透彻的了解。
附:下面这些算法实现的中,我们将假设您懂得Python的基本知识。如果您还不知道Python,可以先看看这个Python教程
强化学习的目的是学习如何做一件事情,以及如何根据不同的情况选择不同的行动。 它的最终结果是为了实现数值回报信号的最大化。强化学习并不告诉学习者采取哪种行动,而是让学习者去发现采取哪种行动能产生最大的回报。 下面让我们通过一个孩子学走的简单例子(下图)来解释什么是强化学习。

首先孩子将观察你是如何行走的。你用两条腿,一步一步走。得到这个概念后,孩子试图模仿你走的样子。
但孩子很快发现,走之前必须站起来!这是一个试图走必经的挑战。所以现在孩子试图先站起来,虽然经历挣扎和滑倒,但仍然决心站起来。
然后还有另一个挑战要应付:站起来很容易,但要保持站立又是另一项挑战!孩子挥舞着双手,似乎是想找到能支撑平衡的地方,设法保持着站立。
现在孩子开始他/她真正的任务走。这是件说比做容易的事。要记住很多要点,比如平衡体重,决定先迈哪个脚,把脚放在哪里。
这听起来像一个困难的任务吗?实际上站起来和开始走确实有点挑战性,但当你走熟练了就不会再觉得走难。不过通过我们的分析,现在的您大概明白了一个孩子学走的困难点。
让我们把的例子描述成一个强化学习的问题(下图)。这个例子的“问题”是走,这个过程中孩子是一个试图通过采取行动(行走)来(孩子行走的表面)的智能体(agent)。他/她试图从一个状态(即他/她采取的每个步骤)到另一个状态。当他/她完成任务的子模块(即采取几个步骤)时,孩子将得到励(让我们说巧克力)。但当他/她不能完成走几步时,他/她就不会收到任何巧克力(亦称负励)。这就是对一个强化学习问题的简单描述。
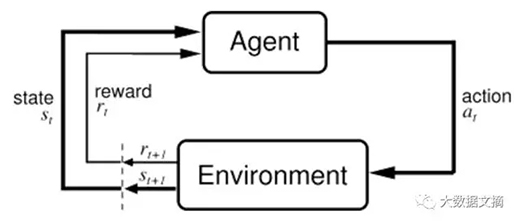
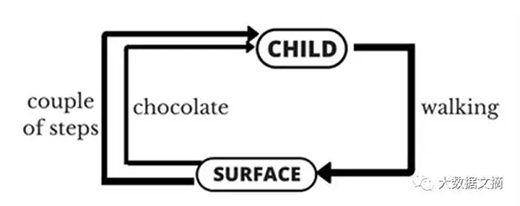
上图:把小孩子学走的过程(图下方)归纳成一个强化学习的问题(图上方)。
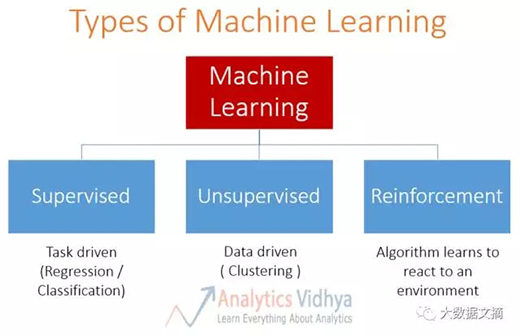
上图:机器学习的方法分类:蓝色方框从左到右依次为监督学习,无监督学习和强化学习。
●监督学习(supervised learning)v.s. 强化学习:在监督学习中,有一个外部“监督者”(supervisor)。“监督者”了解,并与智能体共享信息以完成任务。但这其中存在一些问题,智能体可以通过执行许多种不同子任务的组合来达到目标。所以创建一个“监督者””几乎是不切实际的。例如在象棋游戏中,有成千上万种走法。因此,创建一个可以下象棋的知识库是一个单调乏味的任务。在这样的问题中,从经验中学习更为可行。这可以说是强化学习和监督学习的主要区别。在监督学习和强化学习中,输入和输出之间都存在映射(mapping)。但在强化学习中,还存在对智能体进行反馈的励函数,这在监督学习中是不存在的。
●无监督学习(unsupervised learning) v.s. 强化学习:在强化学习中,有一个从输入到输出的映射。这种映射在无监督学习中并不存在。在无监督学习中,主要任务是找到数据本身的规律而不是映射。例如,如果任务是向用户新闻文章,则无监督学习算法将查看该人先前读过的文章并向他们类似的文章。而强化学习算法将通过少量新闻文章给用户,从用户获得不断的反馈,然后构建一个关于人们喜欢哪些文章的“知识图”。
此外,还有第四种类型的机器学习方法,称为半监督学习(semi-supervised learning),其本质上是监督学习和无监督学习的结合(利用监督学习的标记信息,利用未标记数据的内在特征)。它类似于监督学习和半监督学习,不具有强化学习具备的反馈机制(赏函数)。(注:这里应该是原文作者的笔误,强化学习有映射,映射是每一个状态对应值函数。而无监督学习没有标记信息,可以说是没有映射的。我想这里作者想要表达的是半监督学习区别于强化学习的地方是半监督学习没有强化学习的反馈这个机制。)
为了了解如何解决强化学习问题,我们将分析一个强化学习问题的经典例子多摇臂问题。 首先,我们将去回答探索 v.s. 利用的根本问题,然后继续定义基本框架来解决强化学习的问题。


一个幼稚的方法可能是只选择一个,并拉一整天的杠杆。听起来好无聊,但这种方法可能会给你赢点小钱。你也有可能会中大(几率接近0.00000 ... .1),但大多数时候你可能只是坐在面前亏钱。这种方法的正式定义是一种纯利用(pureexploitation)的方法。这是我们的最佳选择吗?答案是不。
让我们看看另一种方法。我们可以拉每个的杠杆,并向,至少有一个会中。这是另一个幼稚的方法,能让你拉一整天的杠杆,但们只会给你不那么好的收获。正式地,这种方法也被正式定义为一种纯探索(pureexploration)的方法。
这两种方法都不是最优的方法。我们得在它们之间找到适当的平衡以获得最大的回报。这被称为强化学习的探索与利用困境。
在强化学习中定法的数学框架叫做马尔可夫决策过程(Markov Decision Process)。 它被设计为:
我们必须采取行动(A)从我们的开始状态过渡到我们的结束状态(S)。我们采取的每个行动将获得励(R)。 我们的行为可以导致正励或负励。
我们采取的行动的集合(A)定义了我们的策略(),我们得到的励(R)定义了我们的价值(V)。 我们在这里的任务是通过选择正确的策略来最大化我们的励。 所以我们必须对时间t的所有可能的S值最大化。

上图:旅行推销员的例子。AF表示地点,之间的连线上的数字代表在两个地点间的旅行成本。
这显示的是旅行推销员问题。推销员的任务是以尽可能低的成本从地点A到地点F。 这两个之间的每条连线上的数字表示旅行这段距离所需花费的成本。负成本实际上是一些出差的收入。 我们把当推销员执行一个策略累积的总励定义为价值。
● 采取的行动的集合是从一个地方到另一个地方,即{AB,CD等}
现在假设你在A,在这个平台上唯一可见径是你下一目的地的(亦称可观测的空间),除此之外所有都是未知的。
当然你可以用算法选择下一步最有可能的,从{A - (B, C, D, E)}子集中选出{A - D}。同样的你在D,想要到达F,你可以从{D - (B, C, F)}中选择,可以看出由于{D - F}径花费最小,选择此径。
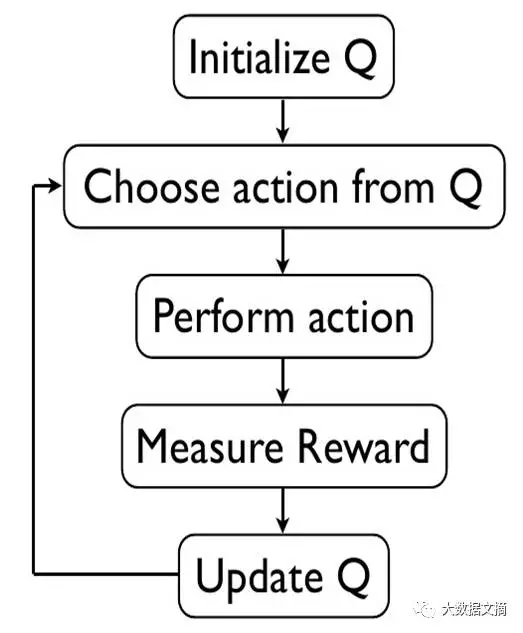
恭喜你!你刚刚完成了一个强化学习算法。这个算法被称作-算法,以方式解决问题。现在如果你(销售人员)想要再次从A到F,你总是会选择相同的策略。
可以看出我们选择的并不是最优策略,我们必须去一点点“探索”来发现最优策略。在这里我们使用的方法是基于策略的学习,我们的任务是在所有可能策略中发现最优策略。解决这个问题有很多不同的方式,简单列举主要类别如下:
我会尝试在以后的文章中更深入地讲述强化学习算法,那时,你们就可以参考这篇强化学习算法调查的文章(。(注:这里是原文作者的一个笔误。Q-learning,它可以用一个线性函数作为function approximator, 也可以通过列举每一个q-state的值来做。用神经网络来做Q-learning的function approximator应该是15年Google Deepmind发表在Nature的文章开始的,那篇文章中称该算法为deep-Q-network,后来统称为deep q learning)
我们会使用深度Q学习算法,Q学习是基于策略的,用神经网络来近似值函数的学习算法。Google使用该算法在Atari游戏中击败了人类。
当我还是一个小孩的时候,我记得我会捡一根试着用一只手让它保持平衡。我和我的朋友们一起比赛看谁让保持平衡的时间最长就可以得到“励”,一块巧克力!
现在你已经有了一个强化学习的基础成品,让我们来进一步的每次增加一点点复杂度以解决更多的问题。

对于不知道该游戏的人简单说明一下发明于1883年,由3根杆及一些逐增大小的圆盘(如上图中所示的3个一样)从最左边的杆开始,目标是从选择最小移动次数将所有圆盘从最左边移动到最右边(你可以从得到更多讯息(。
● 开始状态 3个圆盘都在最左边杆上(从上到下依次为1、2、3)
● 结束状态 3个圆盘都在最右边杆上(从上到下依次为1、2、3)
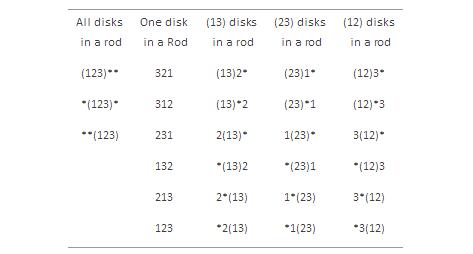
图中(12)3*代表的是圆盘1和圆盘2依次在最左边杆上(从上到下),圆盘3在中间杆上,*表示最右边杆为空
现在,不考虑任何技术细节,我们可以标记出在以上状态间可能出现的转移。例如从励为-1的状态(123)** 到状态 (23)1*,也可以是到状态(23)*1。
同样地,你看出了提到的27个状态的每一个都类似于之前销售人员旅行的示意图。我们可以根据之前的经验找出最优解决方案选择不同状态和径。
当我在为你解决这个问题的同时,也想要你自己也做一做。遵照我使用的相同步骤,你可以更好的理解和掌握。
从定义开始和结束状态开始,接下来,定义所有可能的状态和相应的状态转移励和规则。最后,使用相同的方法你可以提供解决魔方问题的方案。
你已经意识到了魔方问题的复杂度比汉诺塔高了好几个倍,也明白每次可选择的操作数是怎么增长的。现在想想围棋游戏里面状态数和选择,行动起来吧!最近谷歌DeepMind创建了一个深度强化学习算法打败了李世石!
随着近来涌现的深度学习成功案例,焦点慢慢转向了应用深度学习解决强化学习问题。李世石被谷歌deepmind开发的深度强化学习算法开打败的新闻铺天盖地袭来。同样的突破也出现在视频游戏中,已经逼近甚至超出人类级别的准确性。研究仍然同等重要,不管是行业还是学术界的翘楚都在共同完成这个构建更好的学习机器的目标。

随着近期将深度学习应用于强化学习的热潮,毫无疑问还有许多未探索的事在等待着更多的突破来临!

我希望现在你已经对强化学习怎么运行有了一个深入的了解。列举了一些可以帮你探索更多有关强化学习的其他资源:
我希望你们能喜欢阅读这篇文章,如果你们有任何疑虑和问题,请在下面提出。如果你们有强化学习的工作经验请在下面分享出来。通过这篇文章我希望能提供给你们一

